
I've been in enough modernization planning sessions to recognize the pattern. About 20 minutes in, someone asks:
"BigQuery has a migration service—do we really need another platform?"
"Can't we just use DMS and the built-in Snowflake utilities? They're already part of our commitment."
"Our team is strong. Why not handle the conversion ourselves?"
It's a fair question. Cloud vendors have invested heavily in migration tooling. Your engineers are capable. The utilities come bundled. Adding another vendor to the stack needs justification.
I used to think the same way—until I started tracking what actually happens when teams go the native-only route. The data tells a different story than the vendor demos.
Let me walk you through what I've learned.
The Migration Failure Data
Before diving into technical reasons, let's look at outcomes. The research from major analyst firms and industry consortiums is sobering.
What the Numbers Show
Three independent, highly credible sources paint a consistent picture:

Why This Matters
I'm not citing these numbers to create fear. I'm sharing them because they represent real patterns—patterns that show up regardless of industry, company size, or cloud platform.
What connects these failures? When you dig into the root causes, a common theme emerges: teams underestimate complexity and overestimate what basic tooling can handle on its own.
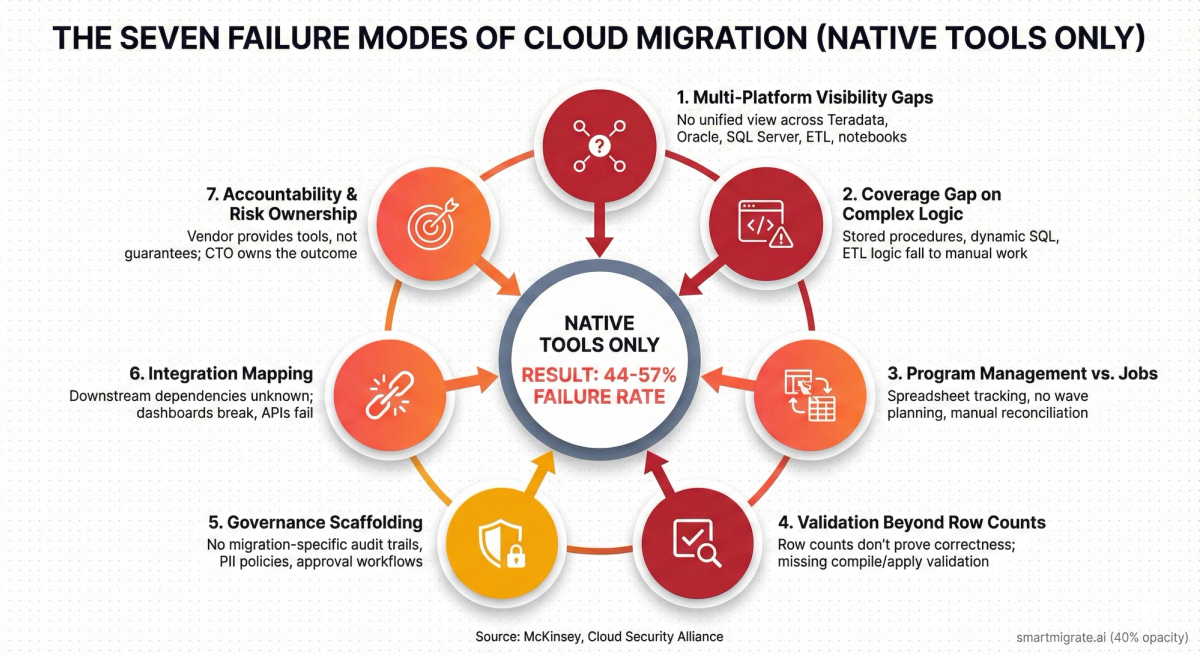
Where Native-Only Approaches Hit Walls
Native tools work well for what they're designed to do. The question is whether what they're designed to do matches what your migration actually needs.
In my experience, the gap shows up in seven places. Not all of these will apply to every migration—but when they do apply, they're the difference between a smooth cutover and a program in trouble.
1. Multi-Platform Visibility Gaps
Native tools are typically designed for one source → one target.
They handle their specific migration path well. The challenge comes when your estate spans:
- Teradata + Oracle + SQL Server
- OLTP databases + data warehouses
- ETL jobs (SSIS, Informatica, DataStage)
- Application SQL embedded across your codebase
- Notebooks (Jupyter, Databricks, Zeppelin)
When you're migrating a single Oracle database to Cloud SQL, this doesn't matter. When you're modernizing an enterprise data estate with multiple source systems, cross-platform dependencies become a blind spot.
I've seen this play out: teams discover hidden dependencies in month six. A Teradata procedure calls an Oracle view. An ETL job references tables across three systems. By the time these surface, timelines are at risk.
2. The Coverage Gap on Complex Logic
Native tools handle the straightforward cases well:
- Simple tables and views
- Basic SELECT queries
- Straightforward schema mappings
Where they run into limitations:
- Stored procedures with complex control flow
- Dynamic SQL that constructs queries at runtime
- Multi-step ETL logic with intricate transformations
- Cross-database joins and dependencies
- Notebooks with embedded business logic
- Proprietary functions and dialect-specific features
This isn't a criticism—these tools were designed for lift-and-shift scenarios. The question is whether your migration fits that model.
For teams with thousands of stored procedures or complex ETL pipelines, the gap between "what the tool handles" and "what needs to be migrated" becomes a staffing and timeline question. I've watched teams spend six figures on manual conversion work for objects the native tool couldn't process.
3. Program Management vs. Job Execution
Native tools typically run individual migration jobs. They're not designed to orchestrate programs.
In practice, this means:
- Wave planning and dependency sequencing happen outside the tool
- Progress tracking relies on external dashboards or spreadsheets
- Retry logic and resume-from-checkpoint need custom scripting
- Executive visibility requires manual reporting
For smaller migrations, this is manageable. For program-scale efforts with hundreds or thousands of objects across multiple waves, the operational overhead adds up.
Teams describe the spreadsheet reconciliation challenge: tracking what's migrated, what's in progress, what failed, and what's blocked—across multiple systems and formats. It's not that it can't be done. It's that it consumes time that could be spent on higher-value work.
4. Validation Beyond Row Counts
Native tools typically offer basic validation:
- Row counts match between source and target? ✓
- Tables exist in the new schema? ✓
But row counts don't prove correctness. Here's where that becomes a problem:
Data reconciliation is necessary but not sufficient. Even if the data moved correctly, you still need to know:
- Does the converted stored procedure compile in the target environment?
- Does the transformed SQL produce a valid execution plan when you run EXPLAIN?
- When you do a dry-run deployment, do dependencies resolve correctly?
- Does the migrated application code actually build after the database changes?
This is where SmartMigrate differs fundamentally. We don't just compare data—we actually:
- Compile converted stored procedures and functions in the target dialect
- Execute dry-runs or use EXPLAIN to validate query plans
- Apply changes to non-prod environments and verify the stack compiles
- Test that application code builds successfully after database schema changes
This catches entire classes of issues that data comparison alone misses: syntax errors the parser didn't catch, semantic mismatches in function behavior, broken cross-schema references, performance regressions from poorly optimized plans.
Manual validation at scale compounds the problem. Checking row counts for 10,000 tables is tedious but possible. Manually compiling and testing 12,000 stored procedures to verify they actually work? That's where teams fall behind.
5. Integration Mapping
Native tools migrate the database. Understanding what depends on that database requires additional work.
This becomes visible when:
- Dashboards go dark because query patterns changed
- APIs fail because stored procedures were renamed or restructured
- Nightly jobs break because they called functions that no longer exist
The integration mapping problem is solvable—you just need to plan for it explicitly rather than discovering it post-cutover.
6. Accountability and Risk Ownership
Here's the reality: cloud vendors provide tools, not guarantees.
When a migration misses its timeline or budget, the accountability sits with your organization. The vendor isn't on the hook for your board presentation.
This isn't unique to native tools—it's true of any migration approach. The question is how much risk you're comfortable owning, and whether the tooling you choose gives you enough visibility and control to manage that risk effectively.
How SmartMigrate Approaches These Challenges
Rather than position this as "we're better," let me explain how we've designed SmartMigrate to address the gaps I just outlined.
A System, Not Just a Tool
SmartMigrate orchestrates three interconnected phases:
- Discover & Assess (SmartExtract, SmartDiscover)
- Automated inventory of objects: stored procedures, ETL jobs, notebooks, schemas
- Complexity scoring and dependency mapping
- Wave planning with risk-aware sequencing
- Convert at Scale (SmartConvert)
- Factory-style translation for notebooks, stored procedures, queries, DDL
- Rule-based patterns with LLM assistance for edge cases
- Built-in review gates for exceptions requiring judgment
- Validate & Deploy (SmartReconcile + Apply)
- Compile converted code in target environment
- Execute dry-runs and EXPLAIN plans
- Apply to non-prod and verify builds
- Data reconciliation and performance benchmarking
Application Context, Not Just SQL
Where native tools work at the SQL layer, SmartMigrate maps at the application layer.
When converting a stored procedure, the system knows:
- Which ETL jobs call it
- Which reports depend on it
- Which downstream systems consume its output
That context helps prevent integration failures that surface post-cutover.
Operated as a Service
The deliverable isn't software to install. It's:
- Wave plans with gating criteria
- Converted code with validation results
- Progress dashboards without manual reconciliation
- Cutover runbooks and rollback procedures
- Operational support from specialists who've run hundreds of these programs
Think of it as bringing methodology and automation together, operated by people who've seen the edge cases.
Native tools are designed for straightforward, single-platform migrations. When your scenario fits that model, they work well.
SmartMigrate is built for program-scale complexity: multi-source estates, thousands of objects, regulatory requirements, and timeline commitments you need to defend.
When to Use Which Approach
Let me be direct: not every migration needs SmartMigrate. Some scenarios are well-suited to native tools.
Here's how I think about the decision:
When Native Tools Might Be Acceptable
✅ Single, isolated workload
Example: One reporting database with <50 objects, no complex dependencies
✅ Low business criticality
Example: Internal analytics sandbox; can tolerate downtime without revenue impact
✅ Simple schema
Example: No stored procedures, no dynamic SQL, no complex ETL logic
✅ Single source → single target
Example: PostgreSQL → Cloud SQL; not part of a broader modernization program
✅ Experimental or POC
Example: You're learning the platform; not committing to production workloads
The Rule: If the migration fails, the impact is contained, the cost is manageable, and you don't have to explain it to your board.
When SmartMigrate (or Equivalent) is Non-Negotiable
❌ Multi-source estates
Example: Teradata + Oracle + SQL Server + embedded app SQL across dozens of systems
❌ Mission-critical systems
Example: Core banking, revenue recognition, customer-facing applications
❌ Complex business logic
Example: Thousands of stored procedures, dynamic SQL, multi-step ETL transformations
❌ Board scrutiny
Example: You've promised a timeline and budget you have to defend quarterly
❌ Regulatory requirements
Example: Audit trails, PII-safe patterns, compliance with SOC 2, GDPR, HIPAA
❌ Program scale
Example: Hundreds or thousands of objects, phased waves, multi-year roadmap
The Rule: If a failed migration would require you to explain to your board why you're asking for another $1M and six months, you need SmartMigrate—not native tools.
The Risk Assessment Question
I opened with the question CTOs ask: "Why not just use the native tools?"
The answer depends on another question: What's your risk tolerance?
If the migration is small, isolated, and low-stakes—native tools might be the right call. You save budget, move quickly, and learn the platform.
If the migration is complex, mission-critical, and under board scrutiny—the calculation changes. The potential downside (budget overruns, timeline slips, post-cutover issues) outweighs the upfront savings.
The decision comes down to asymmetry:
- Upside of native-only: short-term budget savings
- Downside of native-only: project failure, career risk, business impact
I'm not saying native tools always fail. I'm saying the failure patterns are well-documented, and they correlate with the seven gaps I outlined earlier.
Final Thoughts
Native tools have their place. They're essential for simple migrations, learning exercises, and scenarios where the risk is contained.
SmartMigrate exists for the other scenarios—the ones where "we'll figure it out" becomes "we're six months late and asking for more budget."
Your job as a CTO isn't to pick the cheapest option. It's to pick the approach that matches the complexity and risk profile of what you're actually trying to accomplish.
Sometimes that's native tools. Sometimes it's not.
The key is being honest about which scenario you're in—before you're too committed to change course.